Identifying High-Demand Utilities in Virginia: Statistical Learning and National Comparative Analysis in the Era of Data Centers
Paper Overview
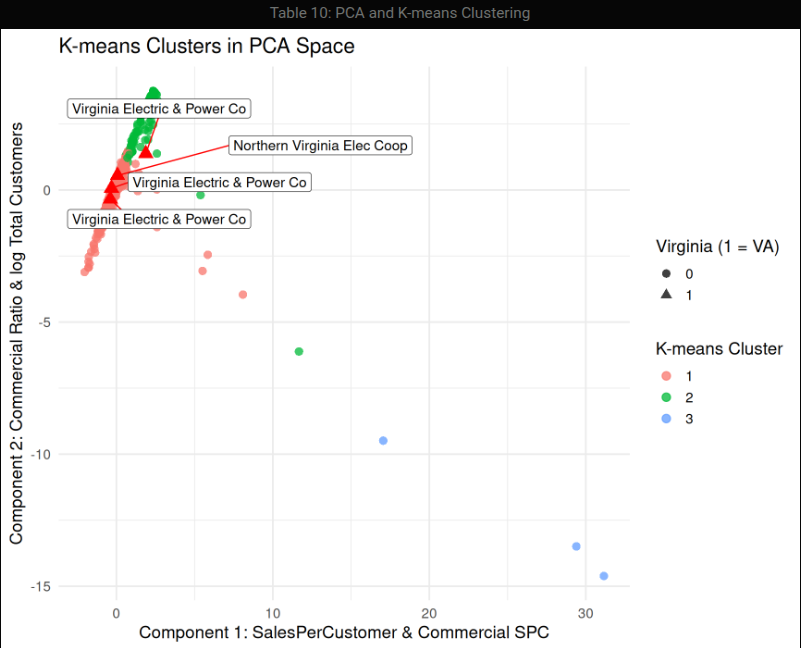
This study examines how the rapid expansion of data centers is reshaping electricity demand in Virginia relative to national utility trends. Using ten years of U.S. Energy Information Administration (EIA-861) data, the project applies statistical learning and machine-learning methods to identify high-demand electric utilities and characterize emerging load patterns associated with commercial and industrial growth.
Key techniques include engineered intensity metrics, supervised classification models (logistic regression, ridge regression, random forests, KNN), and unsupervised methods (PCA and K-means). Results indicate that Virginia exhibits a higher concentration of load-intensive utilities once demand is weighted by commercial activity—consistent with observed data center expansion—while ridge-regularized and tree-based models provide the most stable and interpretable performance.
View the Full Interactive Study
Open the interactive project on GitHub Pages
The full write-up includes interactive visualizations, model diagnostics, and national-scale comparisons.